Karl Jan Clinckspoor
My personal site
Creating a Wordcloud from a Word dissertation
by Karl Jan Clinckspoor
One of my latest projects was to make a film of the evolution of my thesis. One of the
subprojects of this was the creation of a wordcloud from a specific commit of my thesis
repository. This was one of the most attractive parts of film, so my wife asked me to create one
for her dissertation. One problem is that hers was done in Word, not in LaTeX, so I had to adapt
the code. Thankfully, it was relatively painless. I just copy-pasted some functions from
my previous project, created a new virtual environment in wsl with pyenv (see this previous
post)
Requirements: I downloaded a new installation of anaconda3-2020.11, and installed
python-docx, wordcloud, nltk with pip. If you install docx, you’ll get import errors!
You need the latest version.
Here is the code I used. The only pre-processing I did on the text was to manually delete the references. A bunch of undesired English terms were popping up.
import docx # to open the doc file
from wordcloud import WordCloud # to create the wordcloud
from collections import Counter # to count the words
import matplotlib.pyplot as plt # to plot
import re # to extract the words
import nltk # to access the stopwords
# Try
try:
nltk.data.find("corpora/stopwords")
except LookupError:
nltk.download("stopwords")
doc = docx.Document('Mestrado_KarenSlis.docx')
# Extracting the text is relatively easy. I joined the text with spaces, because if I used an
# empty string, it would sometimes join two separate words, and extra spaces don't do anything.
full_text = ' '.join([para.text for para in doc.paragraphs])
# Simplified my project's regex to a very basic one
word_regex = re.compile(r"\b\w+\b")
# Lowered the case of the text, but that led to some problems! Still, it's better to do this and
# revert back later
tokens = word_regex.findall(full_text.lower())
# Other 1 letter words might pop up due to variable names, constants, etc, but these 1 letter
# words actually exist.
acceptable_1_letter_words = ["a", "e", "o", "é", "á", "à", "ó"]
tokens = [word for word in tokens
if (
(
(len(word) == 1)
and (word in acceptable_1_letter_words)
or len(word) > 1
)
)
]
# Remove the stopwords
stopwords = nltk.corpus.stopwords.words('portuguese')
tokens = [word for word in tokens if word not in stopwords]
# Removed some undesired words
undesired_words = ['figura', 'referência']
tokens = [word for word in tokens if word not in undesired_words]
# Count the tokens
frequencies = Counter(tokens)
# Some lower case terms should have been uppercase! Stuff like vitamin names and techniques, so
# I had to revert them back
terms_replace_uppercase = [
'nir', 'mcr', 'b12', 'b6', 'b1',
'matlab', 'hplc', 'gc', 'als',
'ci', 'dpr', 'ifa', 'rmsec'
]
for term in terms_replace_uppercase:
# Switches the term values with tuple assignment
frequencies[term.upper()], frequencies[term] = frequencies[term], 0
# Removes some words that had numbers in them, for some reason, but had to make an exception for
# vitamin names
for key, val in frequencies.items():
if any(map(str.isdecimal, key)) and (key not in ['B12', 'B6', 'B1']):
frequencies[key] = 0
# Some terms were so common, that their plural forms were popping up. She decided to keep the plural
# form and merge the counts
terms_plurals = ['amostra', 'vitamina']
for term in terms_plurals:
frequencies[term+'s'] = frequencies[term] + frequencies[term+'s']
frequencies[term] = 0
# Odd terms - this one was a matrix name, S^T, but I don't know of a way of using superscripts
# or latex in wordcloud, so I removed it.
frequencies['st'] = 0
# On to plotting!
# Selection of colormaps to test
cmaps = ['spring', 'summer', 'autumn', 'winter', 'cool',
'gnuplot', 'hsv', 'nipy_spectral', 'rainbow']
for cmap in cmaps:
cloud = WordCloud(
stopwords={''}, # Stops it from trying to remove english stopwords
width=1920, # Typical 1080p resolution
height=1080,
background_color='white', # We're thinking of printing, so this is saner
relative_scaling=False, # Looked better
colormap=cmap,
random_state=9, # So the wordcloud is reproducible between runs
min_font_size=6 # Fit more words
).generate_from_frequencies(frequencies) # Generates from the Counter object used
fig = plt.figure(figsize=(12, 12/(1920/1080))) # 12 inch by whatever to preserve 1080p ratio
ax = fig.add_axes([0, 0, 1, 1]) # Axes cover the entire figure
ax.imshow(cloud, interpolation='bilinear') # Shows the image
# Removes the ticks everywhere
ax.tick_params(axis='both', which='both', bottom=False, top=False, left=False, right=False, labelbottom=False, labelleft=False)
# Removes the spines/border
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
plt.savefig(f'wordcloud_{cmap}.png', dpi=300) # Saves. Takes about 1 min to run through all.
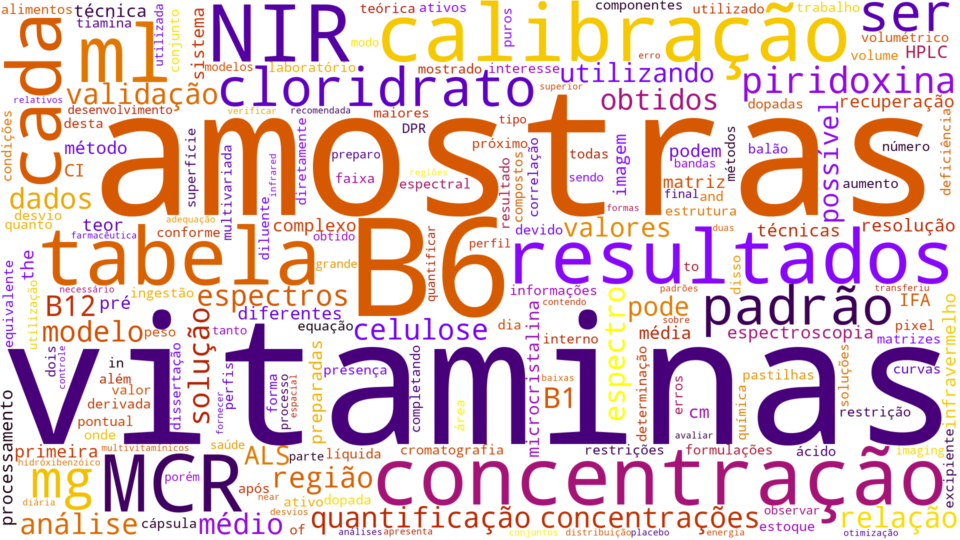
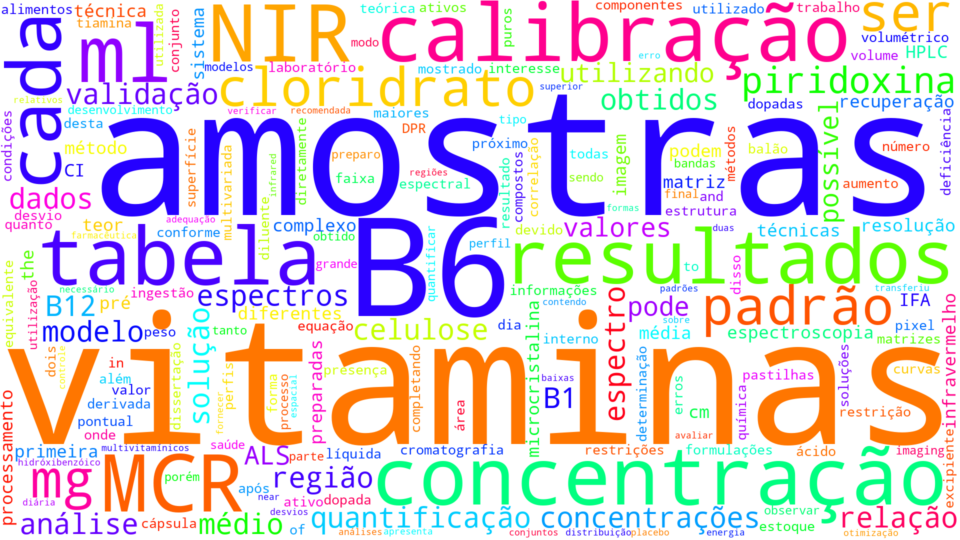
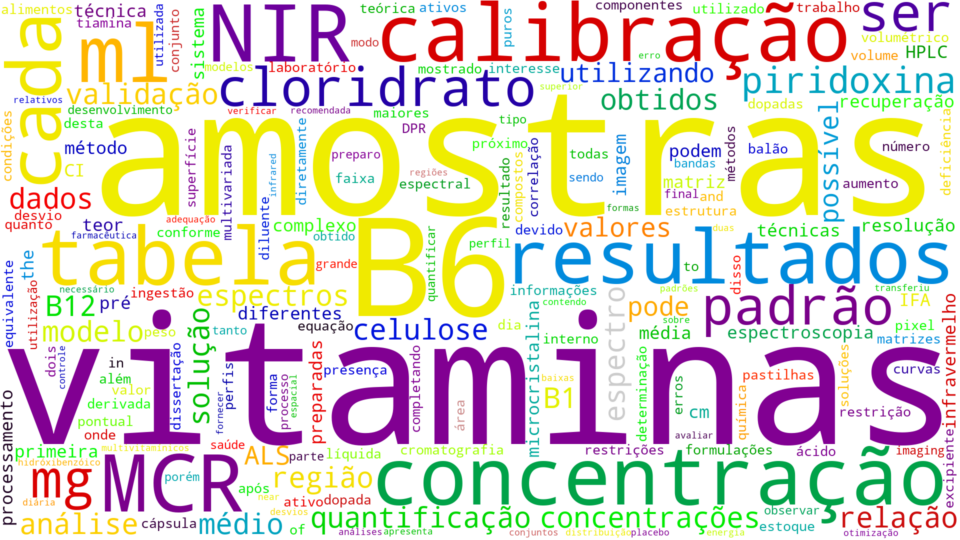
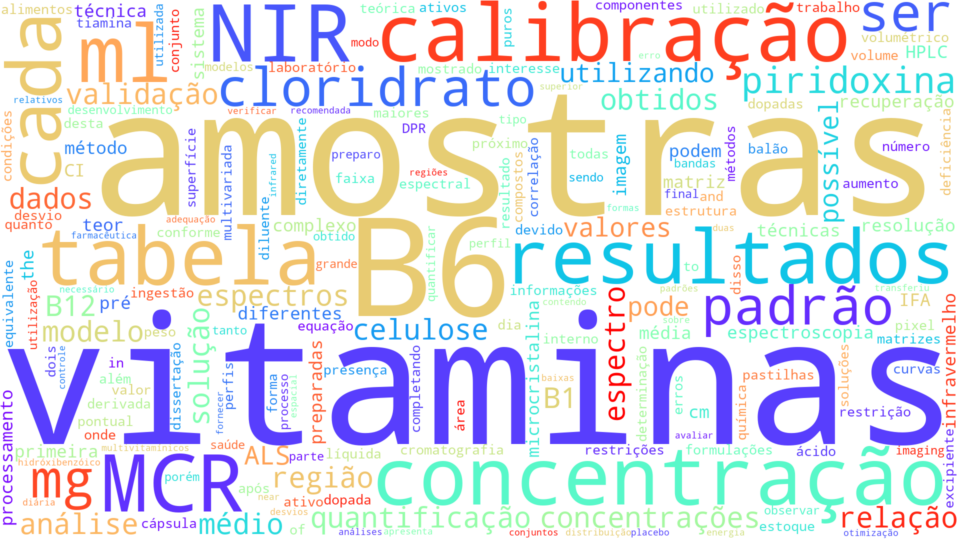
And here’s a result!
|
|
|
|
|
|
|
|
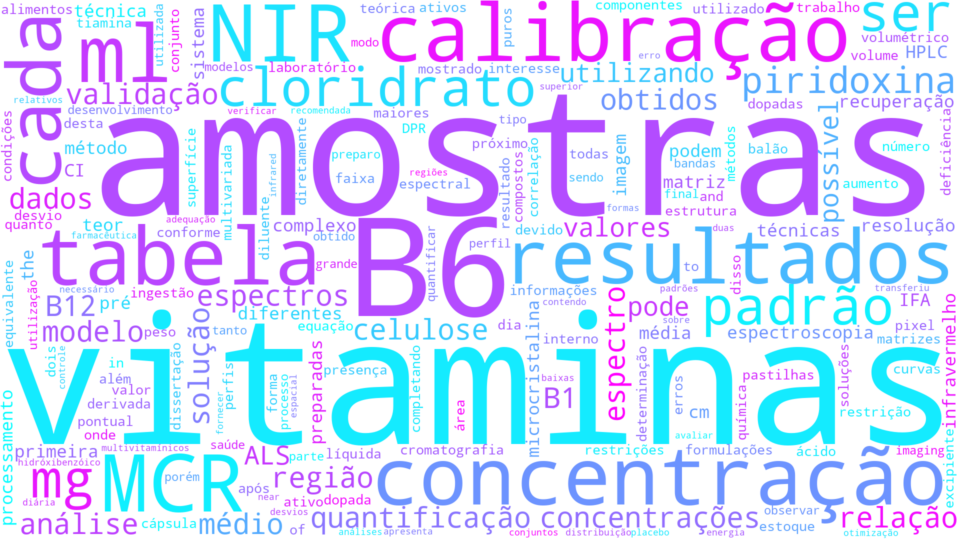
|